科技
2026-04-15
ChenReal
213
玩转本地大模型——MacOS篇
玩过“龙虾”的小伙伴,估计都会为一件事焦虑不已——这玩意太烧Token了!我来教大家一个方法本地搭建大模型,实现Token自由~
玩过“龙虾”的小伙伴,估计都会为一件事焦虑不已——这玩意太烧Token了!随便几个prompt,几百万的Token就灰飞烟灭了。
有人说,我不怕!我有各种CodePlan、TokenPlan的包年包月套餐,按理来说也算是Token自由了吧?
非也,人家那些以盈利为目的的算力平台也不傻呀!不久前,Anthropic首先跳出来,以暴制暴直接封杀了OpenClaw。接着,许多平台都纷纷效仿,有的虽没有Anthropic那样旗帜鲜明的立场,但是暗戳戳下黑手绝对是有的。譬如,以前我用Minimax测试OpenClaw基本还是有问必答的,现在大多对话都返回429了。(HTTP状态码429表示客户端发送的请求过多,超出了服务器的处理能力或限制)
所以,想要真正实现 Token 自由、龙虾自由,在本地部署大模型会是更稳妥的选择。顺着这个思路,我最近一直在测试各种本地模型的搭建方案,算是总结了一点经验,下面就来和大家分享一下~
我的Mac Mini
我现在的主力开发机器是一台去年入手的Mac Mini M4 Pro,虽然只有24G内存,跑30B的模型还是可以的。先折腾一下它。
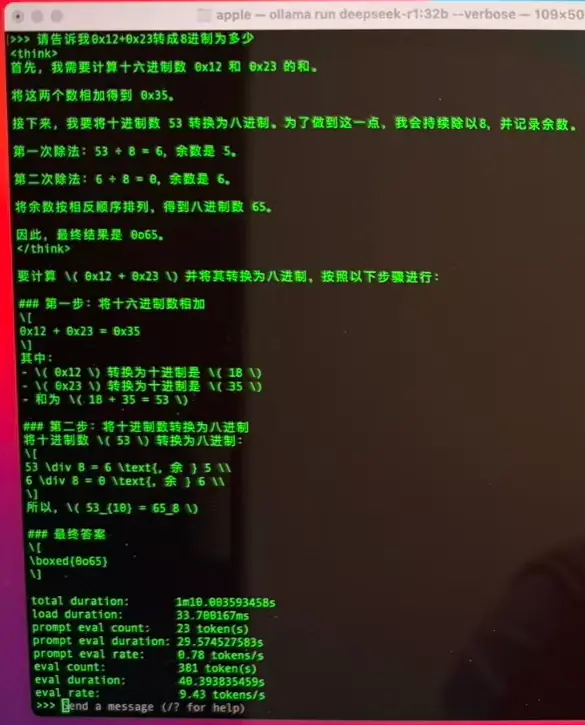
Ollama
记得去年刚刚入手的时候,为了证明我的技能性能还行,花了大几千块还是值的。所以,我安装了Ollama跑了一回DeepSeek 32b的模型,速度大约10 tok/s。勉勉强强吧,不过当时跑本地模型的需求并不强烈,也仅仅浅尝了一把,所以很快就放下了。
LM Studio
转眼到了2026年,本地跑模型的黑科技也越来越多,比如GGUF量化、谷歌TurboQuant上下文压缩算法,这些技术不仅降低了本地部署AI模型的门槛,也让这份折腾多了不少乐趣。
于是我安装了LM Studio,正式开启了我的本地大模型探索之旅。
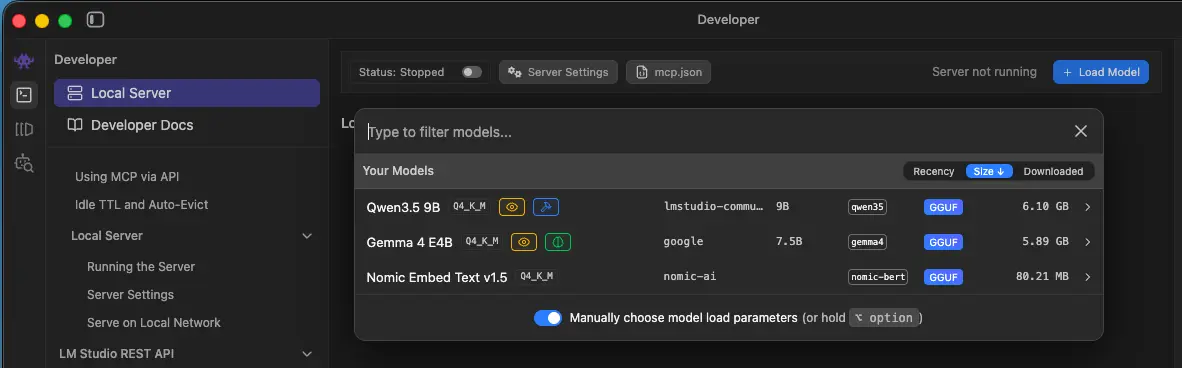
LM Studio是纯GUI界面,功能特别齐全且贴心,从大模型的搜索、下载、运行、测试,到API服务的提供,一条龙服务全包,也是我用过的工具里上手最容易、最适合小白用户的一款。
- 我下载了Qwen3.5-9B的Q4_K_M版本模型,开启64k上下文运行,速度基本稳定在24-25 tok/s,表现很扎实。
- 最近谷歌开源的Gemma4-4B模型,我也拿来实测了一番,速度确实让人眼前一亮!但比起Qwen3.5-9B,它的输出质量差了不止一个档次,尤其是中文内容的输出,差距特别明显。实在搞不懂,最近网上为啥把它吹得天花乱坠,实际体验下来特别扎心,完全没达到大家的预期。
llama.cpp
听说,无论是Ollama还是LM Studio,底层都是llama.cpp。既然如此,如果我直接用llama.cpp,在没有中间商赚差价的情况下,性能会不会有进一步的提升呢?这个可能性很大!
友情提示:llama.cpp没有GUI,是个纯命令行工具,甚至连模型搜索下载功能都没有,所以奉劝技术小白慎用。
而且一般情况下,llama.cpp需要下载源代码编译后才能使用。当然,运气好的话能够找到官方编译好的二进制程序,也可以直接下载运行,省去编译这个环节。
下载地址:https://github.com/ggml-org/llama.cpp/releases
我比较懒,所以直接下载工具来跑。启动脚本如下:
./llama.cpp/llama-server
-m /Users/realchan/.lmstudio/models/lmstudio-community/Qwen3.5-9B-GGUF/Qwen3.5-9B-Q4_K_M.gguf \ # 模型路径(可以重用LLM Studio下载的模型)
-c 32768 \ # 上下文长度,这里定义是32k
-ngl 99 \ # 如果 --n-gpu-layers 90 = 90% 模型放显卡,10% 放 CPU 内存 。对于macOS Apple Silicon的机器应该无所谓的,内存显存是共用的
-t 8
--host 0.0.0.0
--port 8765
--api-key <your_key>
跑起来看看效果,速度达到32-33 tok/s,比LM Studio提升了30%!没有中间商赚差价,才能得到真正的实惠~
oMLX
奥丁同学给我推荐了另外一个工具——oMLX。它是基于Apple Silicon原生的MLX推理框架,我的Mac Mini M4 Pro跑这个再合适不过了!而且还能用上最新的TurboQuant技术。
下载地址:https://github.com/jundot/omlx/releases
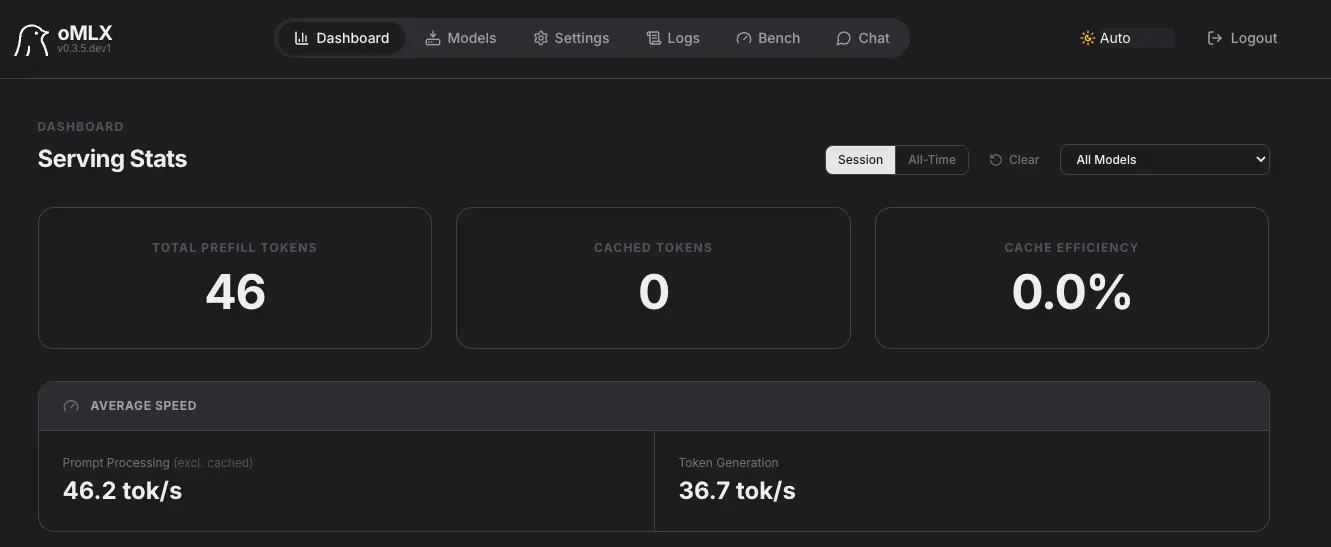
oMLX也提供GUI,模型下载管理、ChatUI、Benchmark一个不少,我个人觉得用起来比LM Studio更舒服!
它的底层不是基于llama.cpp,所以模型跟之前不兼容,需要重新下载。
同样用Qwen3.5-9B来做测试,速度达到了37-38 tok/s,接近40 tok/s了!果然,原配的才是最好的!
总结
为了实现“Token自由”“龙虾自由”,用我的Mac Mini M4 Pro,测试了四款主流本地大模型部署工具,各有优劣:
- Ollama上手简单但速度一般;
- LM Studio GUI友好、功能全面,适合小白,性能中等;
- llama.cpp作为底层工具,无GUI且需手动处理模型,性能强劲,相比LLM Studio速度提升30%;
- oMLX基于Apple Silicon原生MLX框架,兼顾GUI便捷性与性能,同模型测试速度最快,Mac系统首选。
