科技
2026-04-19
ChenReal
106
玩转本地大模型——Linux篇
前几天讲了MacOS系统如何部署本地大模型,今天继续开讲Linux系统。
上回讲了我用MacOS部署本地大模型的实战经历,今天来个姊妹篇,聊聊Linux怎么玩。
首先声明一下,我是按照自己手头上的硬件配置来做实践方案的,不保证绝对通用。如果大家的硬件和我是一个路数,可以参考借鉴。
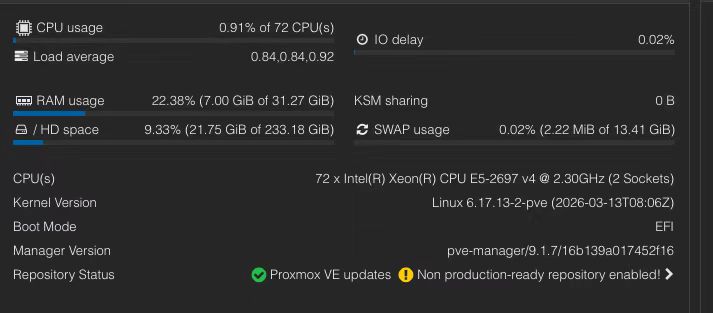
硬件配置
为了响应老板“公司全员养龙虾”的宏愿,波波竟“重金”买了一台2U的服务器回来!还花了400大洋,淘了一张Tesla P4 8G显卡,虽然这显卡性能不怎么样,但拿来跑个几B的小模型,应该还凑合。

系统环境准备
我在服务器上安装的系统是Debian 13。
# 更新系统
sudo apt update && sudo apt upgrade -y
# 安装驱动
sudo apt install -y nvidia-driver-550 nvidia-vaapi-driver
# 重启系统
sudo reboot
- 检查驱动是否安装成功,可以执行
nvidia-smi 命令,能看到显卡硬件信息以及驱动信息,说明驱动安装成功了!那么接下来就可以开始安装CUDA(这个东西关键!给显卡加速用)了:
# 安装 NVIDIA CUDA 工具链
sudo apt install -y nvidia-cuda-toolkit
# 验证一下
nvcc -V
- 接着安装C++的编译环境以及相关工具,我选择用llama.cpp来跑大模型:
# 安装编译依赖
sudo apt install -y build-essential cmake git python3-pip unzip curl git-lfs
- 安装好上面的工具,接着就可以开始从下载源码并编译llama.cpp了:
mkdir ~/build
cd ~/build
# 拉取源代码
git clone https://github.com/ggerganov/llama.cpp
cd llama.cpp
# 开始编译
cmake -B build -DLLAMA_CUDA=ON && cmake --build build --config Release -j$(nproc)
# 创建个工作目录
mkdir ~/ai
# 编译出来的二进制文件放这里
mv ~/build/llama.cpp/build/bin ai/llama.cpp
# 创建模型目录
mkdir ~/ai/models
# 创建日志目录
mkdir ~/ai/logs
下载模型
下载大模型的方法有很多,你甚至可以用LM Studio之类的工具下载好,再传到服务器上——我就是这么做的~
或者直接去Hugging Face下载。如果是国内网络,我个人推荐使用https://www.modelscope.cn(魔搭社区)。另外,我之前已经安装了git-lfs这个git插件,所以也可以通过以下命令行下载模型:
git clone https://www.modelscope.cn/ggml-org/gemma-4-E2B-it-GGUF.git ~/ai/models/gemma-4-E2B
开始服务
好了,环境配好了,工具和模型也都有了,万事俱备!最后我们来准备一个简单的启动脚本。
#!/bin/bash
# ====================== 可配置参数 ======================
ROOT_PATH="/home/chenreal/ai"
LLAMA_PATH="$ROOT_PATH/llama.cpp"
MODEL_PATH="$ROOT_PATH/models/Qwen3.5-9B-Q4_K_M.gguf" # 你的模型路径
LOG_FILE="$ROOT_PATH/logs/llama_server.log"
API_KEY="<你的API_KEY>" # 你的API_KEY
PORT=3333
GPU_LAYERS=90 # Tesla 8G 全量加载
THREADS=36 # E5-2697 v4 18核36线程
CONTEXT_SIZE=65536 # 上下文长度 64 = 65536
#CONTEXT_SIZE=131072 # 上下文长度 128k = 131072
# =======================================================
echo "==================== 启动 llama.cpp server ===================="
echo "模型: $MODEL_PATH"
echo "端口: $PORT"
echo "上下文长度: $CONTEXT_SIZE"
echo "GPU 层: $GPU_LAYERS"
echo "线程: $THREADS"
echo "日志: $LOG_FILE"
echo "==============================================================="
# 后台启动(nohup + 日志)
cd $LLAMA_PATH
nohup ./llama-server \
-m "$MODEL_PATH" \
--port "$PORT" \
--host "0.0.0.0" \
--api-key "$API_KEY" \
--n-gpu-layers "$GPU_LAYERS" \
-t "$THREADS" \
-c "$CONTEXT_SIZE" \
>> "$LOG_FILE" 2>&1 &
echo "启动成功!PID: $!"
echo "实时日志: tail -f $LOG_FILE"
echo "访问地址: http://本机IP:$PORT"
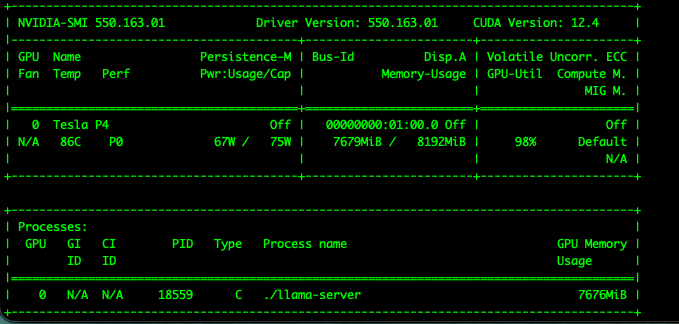
直接执行脚本,我的本地大模型就跑起来啦!输入`nvidia-smi`就能看到显卡资源,已经被9B的大模型占满了。
访问:http://<服务器IP>:3333,进去跟AI聊几句,就能听到服务器风扇嘶吼的声音,还有同事们哗然的惊叹声!
停止服务
如果想切换模型或者调整启动参数,需要先停止刚才启动的llama-server服务,对应的停止脚本我已经准备好了。
#!/bin/bash
pkill -f "llama-server"
echo "llama.cpp 已停止"
总结
简单总结一下,Linux部署本地大模型其实很简单,步骤如下:
- 安装显卡驱动,重启服务器;
- 安装CUDA;
- 安装C++编译环境,通过git下载llama.cpp源代码并编译;
- 将下载好的模型放到服务器上,通过脚本一键启动。
说回我这张Tesla P4显卡,性能确实比较弱,跑千问3.5-9B 4bit量化版本都很勉强,需要降低上下文长度才能正常运行。Qwen3.5-4B 5bit版本稍好一些,但处理并发请求时,依然有显存OOM(内存溢出)的风险。所以,奉劝想玩本地模型的朋友们,先掂量掂量自己的预算,三思而后行。
